Yerli Yapay Zekâ Kumru Tanıtıldı: Türkçe Odaklı Büyük Dil Modeliyle Yeni Dönem Başlıyor
VNGRS tarafından geliştirilen yerli yapay zekâ Kumru tanıtıldı. 7,4 milyar parametreli Türkçe dil modeli düşük donanımda çalışabiliyor. Türkçe LLM Kumru'nun özellikleri, kullanım alanları ve hedefleri.

Kumru'nun geliştiricisi VNGRS, Kumru'yla ilgili merak edilen sorulara cevap vererek ilgiye teşekkür etti.
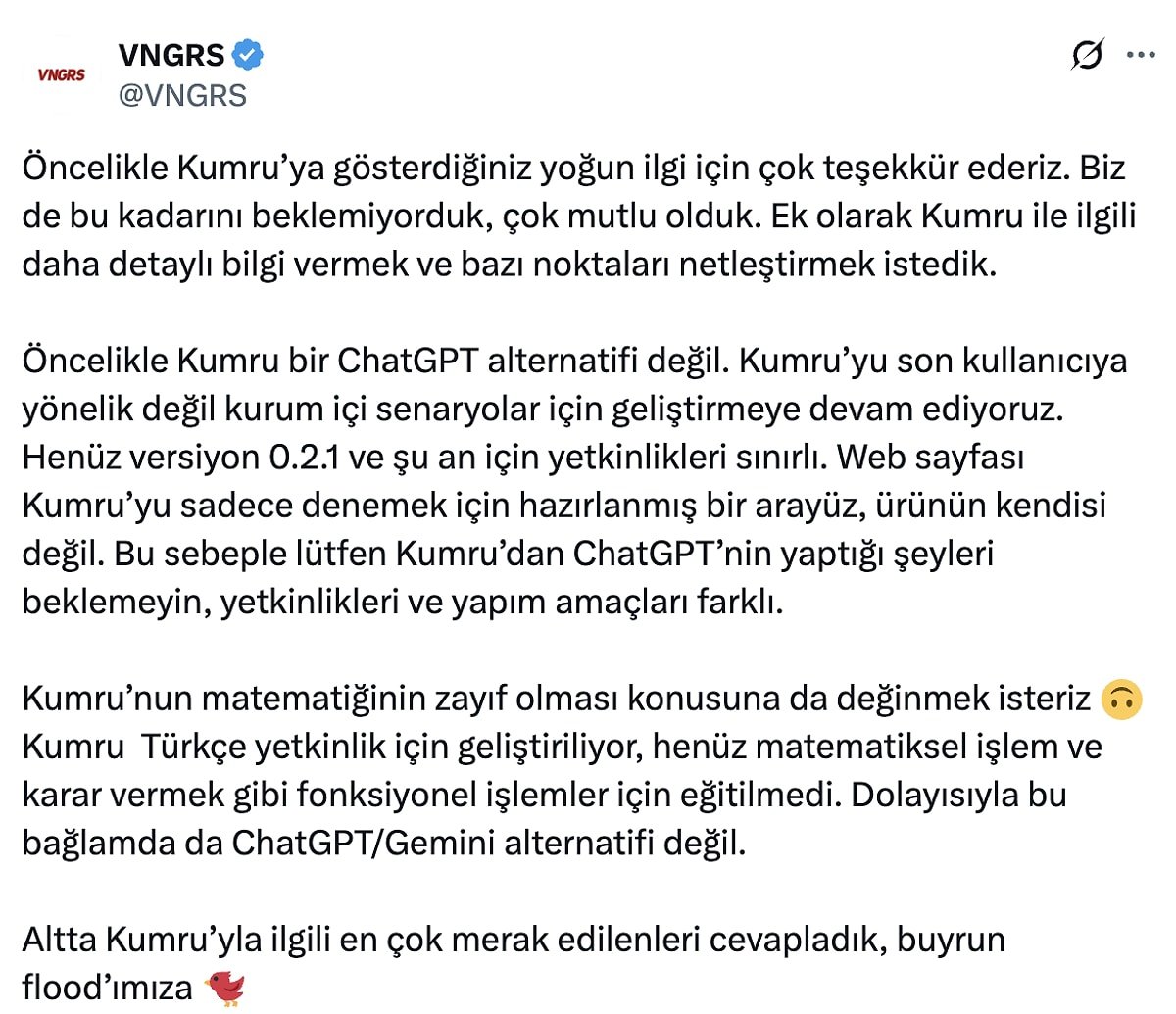
Kumru'nun B2C (Business to Costumer) yani doğrudan müşterilere satış yapma amacı taşımadığını açıklayan VNGRS, bir floodla Kumru'yu anlattı.

Türkiye’de özellikle finans gibi veri güvenliği yüksek sektörlerde faaliyet gösteren birçok kurum, mevcut düzenlemeler nedeniyle ChatGPT benzeri bulut tabanlı yapay zekâ sistemlerini kullanamıyor. Kurum içinde, yani on-premise olarak çalışabilecek açık kaynak dil modellerinin bir kısmı güçlü donanım gerektirdiği için maliyetli, daha küçük olan modeller ise Türkçe konusunda yetersiz kalıyor; çünkü Türkçe bu modellerin ana dili değil.
Bu eksikliği gidermek amacıyla, yüksek donanım yatırımı gerektirmeden çalışabilen ve Türkçe’yi doğrudan ana dil olarak öğrenmiş Kumru modelini geliştirdik.
Kumru, ChatGPT'ye rakip mi?

Kumru’nun zaman zaman hatalı bilgiler üretmesinin nedeni, yapay zekâ alanındaki en karmaşık sorunlardan biri olan “halüsinasyon” problemidir.
Bu durum, modelin gerçekte var olmayan veya yanlış bilgileri doğruymuş gibi sunması anlamına gelir.
Bir yapay zekâ modeli eğitilirken farklı aşamalardan geçer ve son adım olan insan geri bildirimiyle pekiştirmeli öğrenme (Reinforcement Learning from Human Feedback – RLHF), bu tür hataların azaltılmasında kritik öneme sahiptir.
OpenAI’ın ChatGPT’den önce geliştirdiği davinci-001 modeli de aynı aşamadan geçmediği için sık sık benzer hatalar yapıyordu.
Kumru da şu anda aynı aşamada bulunuyor; yani henüz pekiştirmeli öğrenme sürecinden geçmedi.
Bu nedenle zaman zaman yanlış veya eksik bilgiler üretebiliyor. İlerleyen dönemlerde bu aşamanın tamamlanmasıyla modelin doğruluk oranının önemli ölçüde artması bekleniyor.

Model mimarisi, bir derin öğrenme modelinin nasıl yapılandığını belirleyen temel tasarım prensibidir.
Yani bir yapay zekâ modelinde yer alan katmanların (layer) türünü, sayısını ve birbirleriyle nasıl etkileşime geçtiğini tanımlar.
Bu mimari, modelin bilgiyi nasıl işlediğini, öğrenme hızını ve doğruluk oranını doğrudan etkiler.
Mistral ise, son dönemde geliştirilen modern bir büyük dil modeli mimarisidir.
Hafif yapısı sayesinde yüksek performans sunarken donanım açısından da verimlidir.
Kumru, bu Mistral tabanlı yapıyı temel alarak geliştirilmiştir; böylece hem daha hızlı işlem yapabilen hem de daha düşük donanımla çalışabilen bir Türkçe dil modeli ortaya çıkmıştır.
Kumru'nun Güçlü ve Zayıf Olduğu İşler Neler?

Kumru’nun matematiksel işlemlerde zayıf olmasının temel nedeni, bir hesaplama aracı değil, bir dil modeli olmasıdır.
Dil modelleri, sözcükler ve kelime parçacıkları (token) üzerinden çalışır; öğrendikleri bilgileri devasa metin veri kümelerinden istatistiksel olasılıklar yoluyla edinirler.
Yani bir işlemi gerçekten “hesaplamazlar” — yalnızca eğitim verilerinde gördükleri örneklerden yola çıkarak en olası sonucu tahmin ederler.
Bu nedenle, modelin içinde gerçek bir hesap makinesi mantığı bulunmadığından, matematiksel problemlerde sık sık hatalı sonuçlar ortaya çıkabilir.
Aslında Kumru, neyi bildiğini veya bilmediğini ayırt edemeyen, sözcükler üzerinden tahmin yürüten “konuşkan bir metin üreticisi”dir.
Benzer durum, ChatGPT ve diğer erken dönem dil modellerinde de yaşanmıştı.
Ancak bu modeller, zamanla pekiştirmeli öğrenme (Reinforcement Learning) aşamalarından geçerek daha doğru sonuçlar üretebilir hale geldiler.
Kumru da aynı süreci tamamladığında, özellikle matematiksel işlem ve mantık yürütme konularında çok daha başarılı sonuçlar verecek.
Kumru'ya Verdiğim Kelimedeki Harfleri Sorunca Yanlış Cevap Veriyor, Neden?

2 milyar ve 7 milyar parametreli modeller arasındaki temel fark, öğrenme kapasitesi ve bilgi derinliğidir.
Her iki model aynı eğitim verisini, aynı bağlam uzunluğunu (context length) ve aynı tokenizer yapısını kullanıyor olsa da, sahip oldukları parametre sayısı modellerin beceri düzeyini belirler.
Bir yapay zekâ modelinde “parametre”, modelin öğrendiği bağlantılar ve ağırlıklardır.
Parametre sayısı ne kadar fazlaysa, model o kadar fazla örnekten kalıp çıkarabilir, daha karmaşık ilişkileri anlayabilir ve dilin inceliklerine daha doğru yanıtlar verebilir.
Bu nedenle 7 milyar parametreye sahip model, 2 milyarlık versiyona göre daha fazla bilgiye sahip, daha isabetli sonuçlar üreten ve bağlamsal anlamda daha “akıllı” bir yapı sunar.
Kısacası, iki model aynı altyapıya sahip olsa da büyüklük farkı, öğrenme gücü ve yanıt kalitesinde belirleyici bir rol oynar.

LLaMA gibi mevcut bir modeli alıp üzerine continual pre-training (sürekli yeniden eğitim) yapmak aslında oldukça mantıklı bir yöntem — nitekim Türkiye’deki birçok ekip de bu yaklaşımı tercih ediyor.
Ancak bu yöntemin bazı teknik sınırlamaları var. En önemlisi, orijinal modelin tokenizer’ını kullanma zorunluluğu.
Bu durum Türkçe için ciddi bir verimsizlik yaratıyor. Çünkü İngilizce tabanlı tokenizer’lar, Türkçe kelimeleri parçalamakta zorlanıyor ve aynı cümleyi işlerken çok daha fazla token üretiyor.
Bu da hem modelin eğitilme süresini hem de kullanım maliyetini neredeyse iki katına çıkarıyor.
Elbette var olan bir modelin embedding matrix’i ve tokenizer’ı üzerinde değişiklik yaparak Türkçe’ye kısmen uyarlamak mümkün,
ancak bu yöntem bir noktadan sonra modelin iç dengesini bozuyor ve tokenizer ile model arasındaki bağ kopmaya başlıyor.
Bu nedenle biz, sıfırdan Türkçe için özel olarak optimize edilmiş bir yapı kurmayı tercih ettik.
Kumru’nun eğitimi için modern, Türkçe dil kurallarına uygun, kod ve matematik desteği içeren,
tamamen kendi geliştirdiğimiz bir LLM tokenizer oluşturduk.
Böylece hem eğitim sürecinde tam kontrol sağladık hem de Türkçe’ye özgü dil yapısını derinlemesine işleyebilen bir model ortaya koyduk.
Ayrıca bu süreci baştan sona yürütmek, ekibimize yerli LLM geliştirme konusunda değerli bir bilgi birikimi kazandırdı.

Kumru’nun eğitiminde ağırlıklı olarak Mart 2024’e kadar üretilmiş Türkçe metin verileri kullanıldı.
Bu veri kümesi; Türkçe web içerikleri, Wikipedia makaleleri, haber metinleri, blog yazıları ve çeşitli kamuya açık literatür kaynaklarından derlendi.
Amaç, modelin Türkçe’nin tüm dil yapısına —günlük konuşma dilinden akademik metinlere kadar— hâkim olmasını sağlamaktı.
Ek olarak, modelin genel dil anlama ve teknik kavramlarda da başarılı olabilmesi için eğitim verisinin yaklaşık %5’lik kısmına İngilizce metinler ve yazılım kodları dahil edildi.
Bu karışım sayesinde Kumru, hem Türkçe odaklı doğal dil görevlerinde yüksek doğruluk elde edebiliyor
hem de kod, matematik ve teknik açıklama gerektiren metinlerde tatmin edici bir performans sergileyebiliyor.
Kumru Nasıl Geliştirildi?

7 milyarlık modeli de açık kaynak yayınlayacak mısınız?
Evet, planlamalar arasında bu adım da yer alıyor.
Kumru ekibi, gelecekte daha büyük ve çok modlu (multimodal) modeller geliştirdikçe, önceki sürümleri kademeli olarak açık kaynak hâline getirmeyi hedefliyor.
Bu kapsamda, 7 milyar parametreli modelin de ilerleyen süreçte toplulukla paylaşılması planlanıyor.
Bu stratejiyle amaçlanan şey, hem araştırmacılara hem de geliştiricilere Türkçe odaklı güçlü bir temel sunmak ve yerli yapay zekâ ekosisteminin büyümesini desteklemek.
Açık kaynak yaklaşımı sayesinde, Kumru’nun ilerleyen sürümleri yalnızca VNGRS tarafından değil, bağımsız araştırmacılar tarafından da geliştirilebilecek.